Finding hacked web servers with ssh log files

Finding hacked web servers with ssh log files.#
After making a server available to the internet, especially on a
shared host you immediately get hit with automated ssh login requests.
To view these attempts on Debian based systems by grepping for the words "Invalid user"
or "authentication failure" in the /var/log/ directory
grep "Invalid user" /var/log/auth.log
Sep 30 14:56:18 joesite sshd[31553]: Invalid user ubuntu from `205.185.114.141 port 46502
Sep 30 14:56:30 joesite sshd[31557]: Invalid user ansible from 205.185.114.14`1 port 33304
Sep 30 14:56:42 joesite sshd[31561]: Invalid user oracle from 205.185.114.141 port 48326
Sep 30 14:56:59 joesite sshd[31568]: Invalid user ftpadmin from 205.185.114.141 port 42644
Sep 30 14:57:05 joesite sshd[31570]: Invalid user test from 205.185.114.141 port 50166
Sep 30 14:57:10 joesite sshd[31572]: Invalid user testuser from 205.185.114.141 port 57680
Sep 30 14:57:16 joesite sshd[31574]: Invalid user weblogic from 205.185.114.141 port 36956
Sep 30 14:57:23 joesite sshd[31576]: Invalid user user from 205.185.114.141 port 44472
Sep 30 14:57:28 joesite sshd[31578]: Invalid user ts3 from 205.185.114.141 port 51988
The format of these log files looks like this
[Time][Hostname][daemon][pid]:[Message][username][ip][port number]
I want to dig a little deeper.#
Where do these malicious requests come from? It’s safe to assume that most of these are automated with some simple python script. But I’m interested to see how many of these login requests are from other shared hosting environments like web servers. An attack coming from the some random starbucks wifi network or the basement of some 16 year old H4x0r’s basement is less concerning than an attack coming from a hacked webserver, because the latter implies a much higher level of sophistication.
To start I first needed a large dataset IP addresses so wrote a bash script that runs on
a cron tab every 3 or so days that backs up all the files
that start with auth in my /var/log/ directory.
backup_ssh_auth_logs(){
time_stamp=$(date +'%m_%d_%Y_%H_%M')
save_dir="/root/logs/auth/$time_stamp"
mkdir $save_dir
cp /var/log/auth.log* $save_dir
wait
cd /root/logs/auth
7z a $time_stamp
rm -rf $time_stamp
}
This bash script will make a directory with the current time, copy all files
in /var/log/ that start with auth to a directory with the current time,
then it adds them a p7zip archive.
Unpacking the archives to bring these files to my local machine I use rsync
rsync -avz nj:/root/logs .
I then do every thing I did remotely in reverse with the addition of extracting
gzip archives (which Nginx makes my default) and renaming all the files so that they
end with .log
unzip all archives in directory
for i in *.7z; do 7z x -o"$i""_dir" $i ;done
guzip all gzip archives
gzip -d *.gz
rename files ending with numeric values
for i in *.{1..4}; do mv $i $i.log; done
Combining the log files#
Each one of these log files contained between 9k-32k lines
$ for i in *.log; do wc -l $i; done
2881 auth.log
17521 auth.log.2.log
39566 auth.log.3.log
9693 auth.log.4.log
12906 auth_2.log``
To make things easier to work with I appended all the log files to one log file named
all_logs which was about 82k lines long.
$ for i in *.log; do cat $i >> all_logs.log; done
$ wc -l all_logs.log
82567 all_logs.log
Cleaning up the data#
Some of these requests were legit attempts from me to login
so I removed all lines from this file that didn’t contain the words
Invalid user from the file using grep
grep "Invalid user" all_logs.log >> all_invalid_users.log
After this the file moves from 82k to around 25k
wc -l all_invalid_users.log
24928 all_invalid_users.log
dealing with duplicates
When I looked at the new log file I noticed that most of these attacks attempted several combinations of username and password, resulting in a new log entry from the same IP. Before I could remove the duplicates I needed to extract only IPs from the log file. I did this with a grep pattern that extracts only the ip address from each line.
grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' all_invalid_users.log >> all_ips.txt
After this I was left with a file that has the same amount of lines
as all_invalid_users.log but with only ip addresses.
82.196.5.221
104.244.75.62
104.244.75.62
104.244.75.62
176.111.173.237
To remove the duplicates from this file I used a combination of the sort and uniq commands which took the ip list down from 25k to 3,707.
$ sort all_ips.txt | uniq -u >> uniq_ips.txt
$ wc -l uniq_ips.txt
3707 uniq_ips.txt
Removing Tor exit nodes#
Now that I had a list of unique IP addresses the first thing I did was cross out the usually suspects. Tor Exit nodes. Tor is network of computers run by volunteers that allows people to access the web “somewhat” anonymously by routing traffic through a series of nodes ending in an exit node. Exit nodes are the computers in the network that that do the job of routing whatever traffic is sent through, to the clear-net. Exit nodes do not know who is sending requests, they just act as a middle man between tor users and the open internet. Unfortunately this means they often get blamed for malicious requests sent from their server.
To find out how many of these requests are from exit nodes I compared an up to date list of exit nodes
(provided by the tor project) to our current list of IPs using a combination of the sort and uniq
commands.
# grab the list of exit nodes
wget https://check.torproject.org/torbulkexitlist
cat torbulkexitlist uniq_ips.txt| sort | uniq -d >> tor_nodes_attempting.txt
wc -l tor_nodes_attempting.txt
0 tor_nodes_attempting.txt
It seems the the tor network has not deemed me a credible target. Let’s hope it stays like that.
Finding domains and hosting providers#
The next thing I tried, was to associate these IP associate with domain names. It’s pretty easy to find the IP associated with a given a domain name using the dig command.
dig notjoemartinez.com
; <<>> DiG 9.10.6 <<>> notjoemartinez.com
;; ANSWER SECTION:
notjoemartinez.com. 300 IN A 216.128.130.165
However, finding the domain name of a given ip is a different challenge because:
- Most ip addresses are not associated with domains
- Domain Names are often associated with different IPs, especially when you start considering load balancing on larger web applications.
NSlookup#
There is this tool nslookup that can be used to give you some more
information on a given ip address. Most of the time it won’t return the top level domain
but it will often return some information about the hosting provider.
Using only the IP of my web server I’m able to find that it is hosted using vultur.com,
similar things will appear with digital ocean, aws, lenode etc..
nslookup 216.128.130.165
Server: 129.118.1.47
Address: 129.118.1.47#53
Non-authoritative answer:
165.130.128.216.in-addr.arpa name = 216.128.130.165.vultr.com.
I could use this to report each machine to its hosting provider but this is usually not worth your time unless you’re losing a bunch of money or something.
Finding web servers#
Now that I had a list of over 3k malicious IPs I needed a way to sort out those running web servers. I could have ran a port scan on each IP but not only would that take forever, it would probably put me on some other sysadmins malicious IP list. The goal of the port scan is to find servers with an open port of 80 or 443 which are the ports used by http and https meaning that they are running a web server. But an even faster way to check if an IP is running a web server is to just send it an http get request. If it returns a code 200, it’s probably a web server. I wrote this python script to do exactly that. It iterates through my text file of IPs and adds the result of the get request to a database. the code for everything is linked at the bottom of this post
def check_webserver(file_path):
with open(file_path, 'r') as f:
lines = f.readlines()
random.shuffle(lines)
for count, ip in enumerate(lines):
ip = ip.strip()
progress(count,len(lines))
try:
resp = requests.get(f"http://{ip}", timeout=5)
html = resp.text
add_ip_to_db(ip,"true",html)
with open("scanner.log", "a") as f:
f.write(ip+"\n")
except requests.exceptions.RequestException as e:
add_ip_to_db(ip,"false", "")
with open("scanner.log", "a") as f:
f.write(ip+"\n")
pass
The above script also saves the raw html of whatever is returned by the get
request, this is what the database looks like:
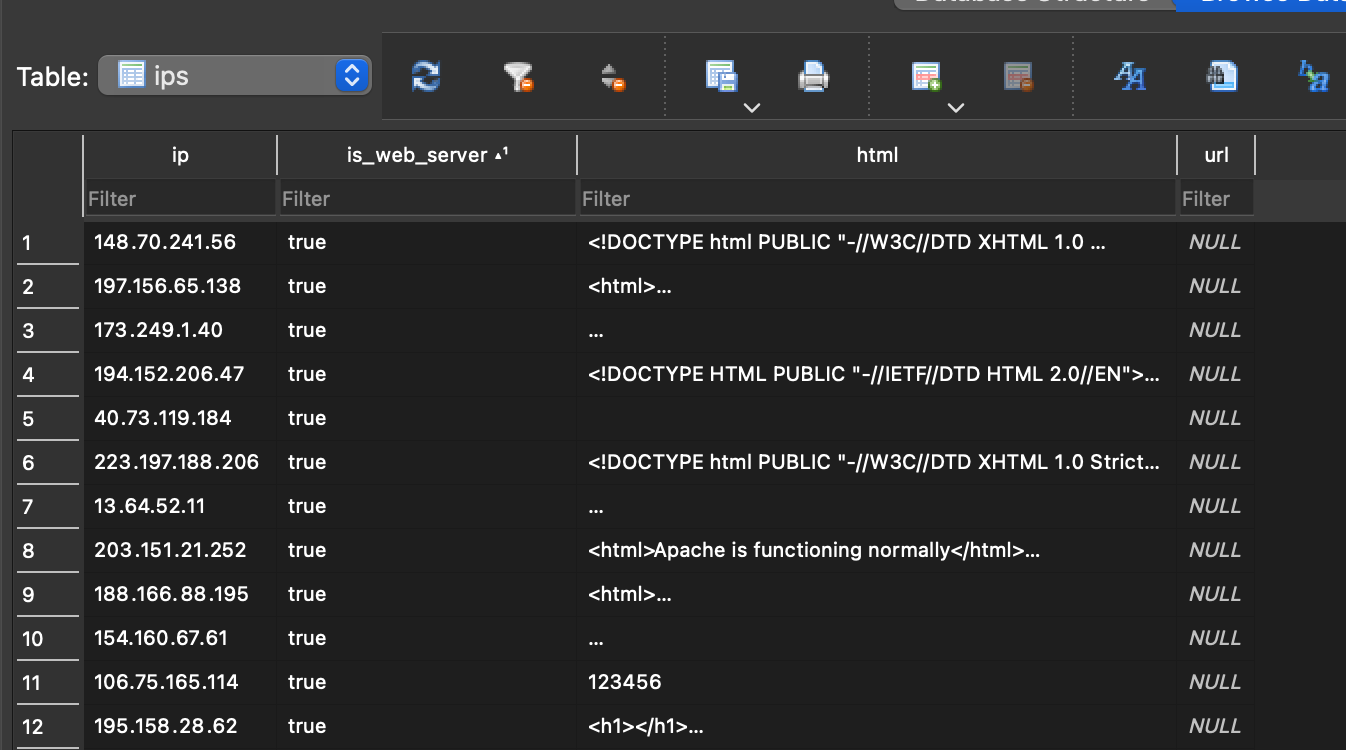
filtering IPs from database
To filter out the IPs with web servers we can run the following sqlite query on the database which takes our list down 507 uniqe IP addresses
sqlite3 ipinfo.db "select ip from ips where is_web_server='true'" >> ips_with_webservers.txt
wc -l ips_with_webservers.txt
507 ips_with_webservers.txt
Automating viewing the web servers#
Rather than manually look at all 507 of these web servers through a browser wrote a script that uses the selenium web driver to screen shot the default home page of each IP address.
def run_driver(ip_list):
browser = webdriver.Firefox()
browser.set_page_load_timeout(MAX_TIMEOUT_SECONDS)
ips_found = os.listdir("screenshots")
ips_found = [foo[:-4] for foo in ips_found]
for ip in ip_list:
if ip not in ips_found:
try:
print(f"Getting {ip}")
browser.get(f'http://{ip}')
print("waiting")
time.sleep(4)
browser.save_screenshot(f'screenshots/{ip}.png')
url_text = browser.current_url
with open("urls.txt", "a") as f:
f.write(f"{url_text}\n")
overlay_url(url_text, ip)
print(f"saving screenshot to screenshots/{ip}.png")
except TimeoutException:
continue
except:
continue
browser.quit()
What I found#
Default Webserver Pages
By far the most common thing I found was default nginx and apache landing pages

Another common thing was phpinfo pages
Pet Projects & Abandoned CMS
I was somewhat surprised to see a lot “corporate” looking websites from different countries. But upon closer investigation I found most of these were default CMS themes with Lorum Ipsum text and stock photos meaning they were probably just staging sites. However there were a couple of business sites I confirmed were real. This brought be back to my days slinging overpriced WordPress sites to boomers. I would often set up a staging server with the free theme and send the ip to my client to show what it will look like. Odds are I did not secure those sites properly.
I also found a lot of “demo day” CRUD applications and database guis.
The More Concerning Stuff#
Windows machines

Nextcloud instances
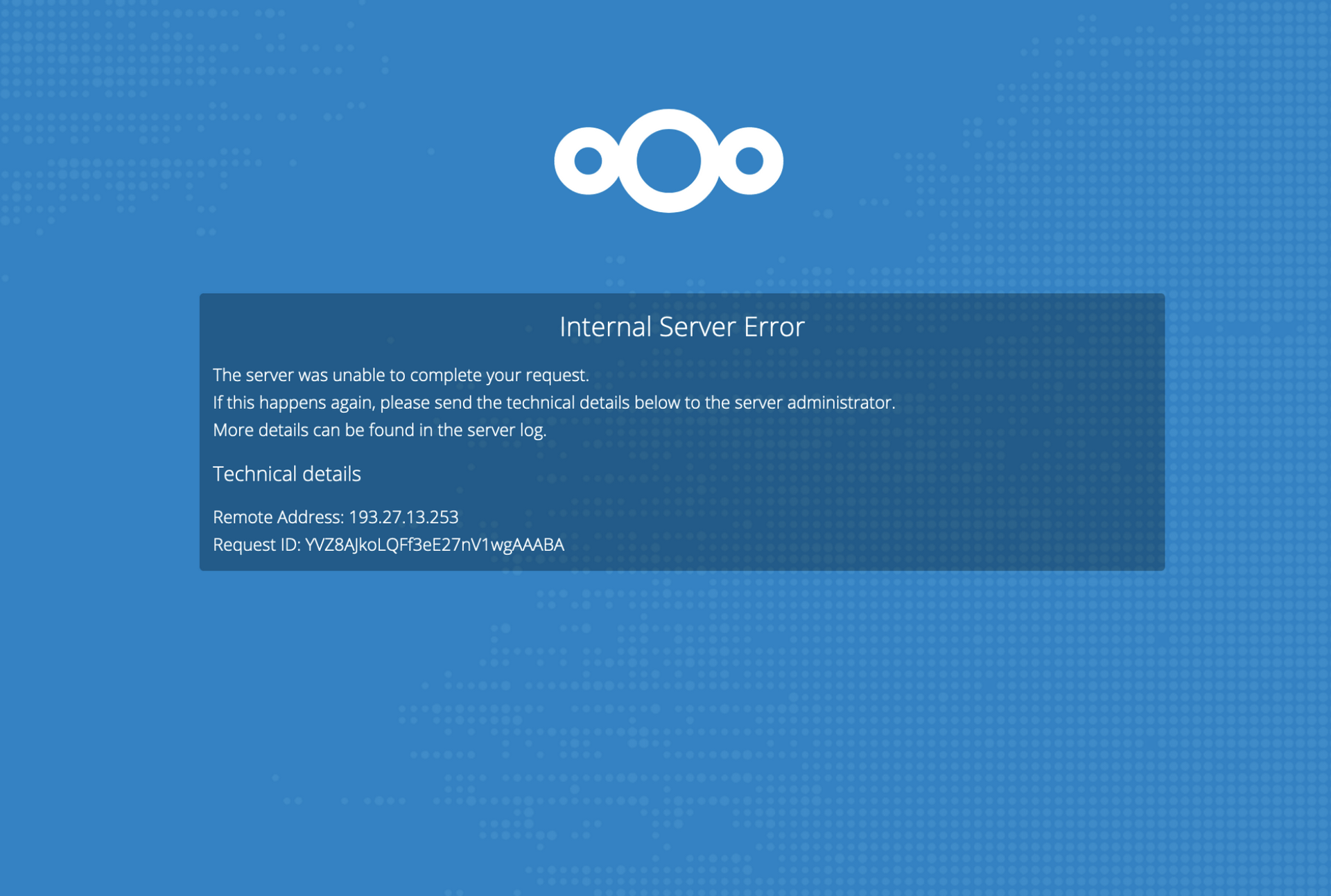
Router Admin Pages
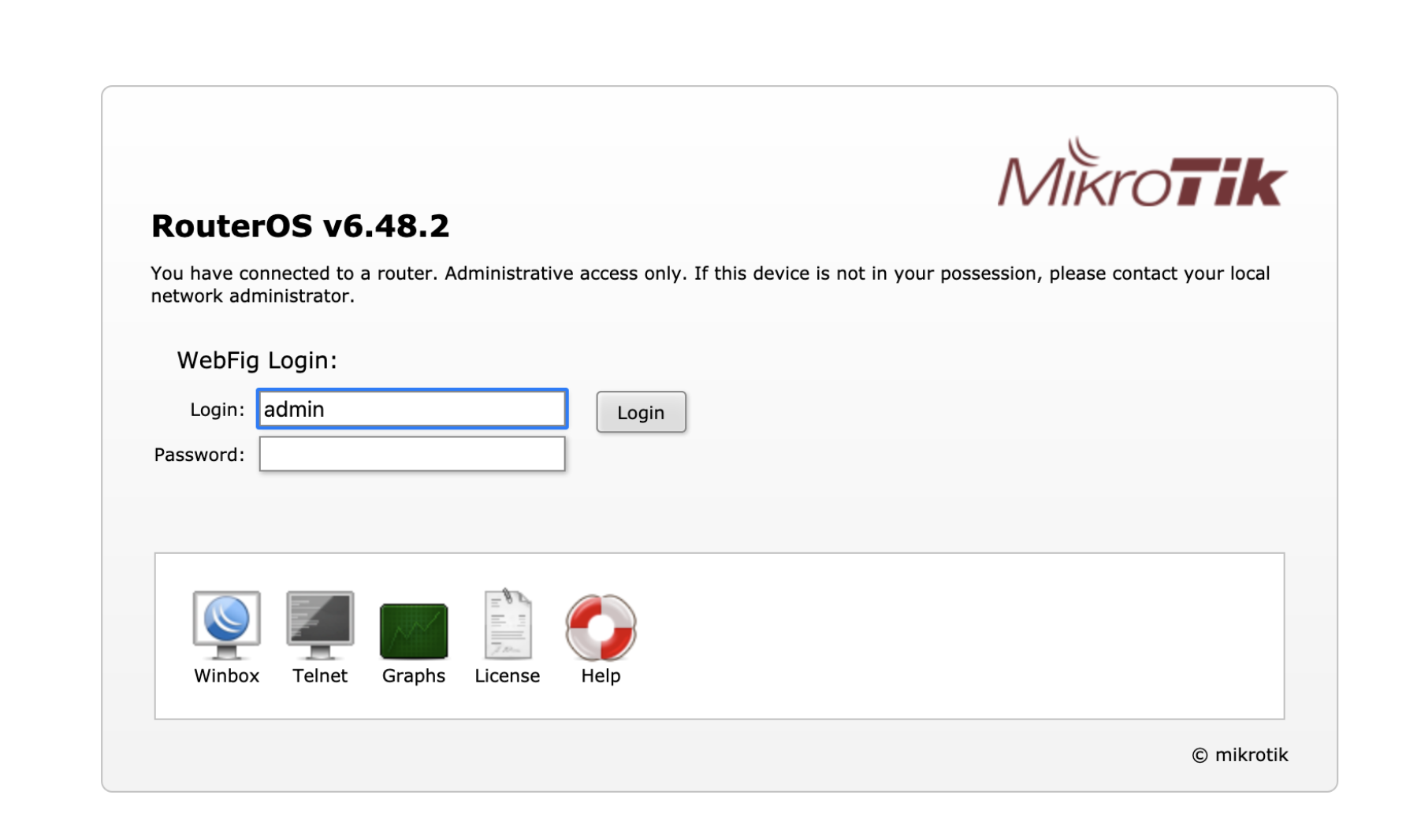
The weird shit#
I don’t why would you ever need a dashboard like this, much less one that connects to
the internet. God save us.