Use full text search on youtube channles with yt-dlp

Update:
I recently made a better python script using the ideas in this blog post: https://github.com/NotJoeMartinez/yt-fts
yt-dlp is a tool that can be used to download youtube videos.
yt-dlp -f mp4 "https://youtu.be/jXow8M_8LJE"
It also lets you download the auto generated captions from youtube. With the --write-auto-subs flag and you can skip downloading the video with --skip-download
yt-dlp --write-auto-sub --skip-download "https://youtu.be/jXow8M_8LJE"
this will spit out a .vtt (Web Video Text Tracks) file formatted like this
WEBVTT
Kind: captions
Language: en
00:00:00.640 --> 00:00:03.830 align:start position:0%
and<00:00:01.120><c> now</c><00:00:02.320><c> tim</c><00:00:02.800><c> dillon</c><00:00:03.439><c> is</c>
00:00:03.830 --> 00:00:03.840 align:start position:0%
and now tim dillon is
00:00:00.640 --> 00:00:03.830 represents the time span of where a statement is said, the following line is the transcription of what was said on that line with some mark up tags. The next line repeats this without markup tags and a less accurate time span. I haven’t found a way to download them without markup tags. This means youtube can technically be used as a free substitute for googles speech to text api although if a creator uploads their own captions, the quality of the auto generated captions falls significantly. If you know a creator uploaded captions with their video
you can download them instead of the auto generated captions with --write-subs.
You can make a csv file with the video id and the title of the video like this:
yt-dlp --print "youtu.be/%(id)s;%(title)s" "https://www.youtube.com/channel/UC4woSp8ITBoYDmjkukhEhxg/videos" >> tim_dillon.csv
9Gly30LrUaE;#220 - Hail Mary | The Tim Dillon Show
G_LpoF9awAE;JFK Tour Guide Tells All
CT5mNKVpja8;#219 - The Gates Of Hell | The Tim Dillon Show
b1I42xTIOCQ;#218 - Fake Business | The Tim Dillon Show
Youtube video ids are unique strings at the end of the base url
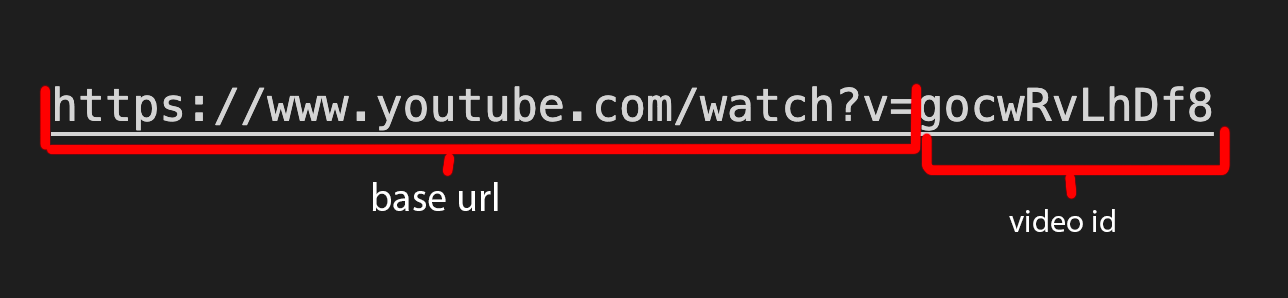
when you share a video you get a shortened base url with the same video id.
https://youtu.be/[videoid]
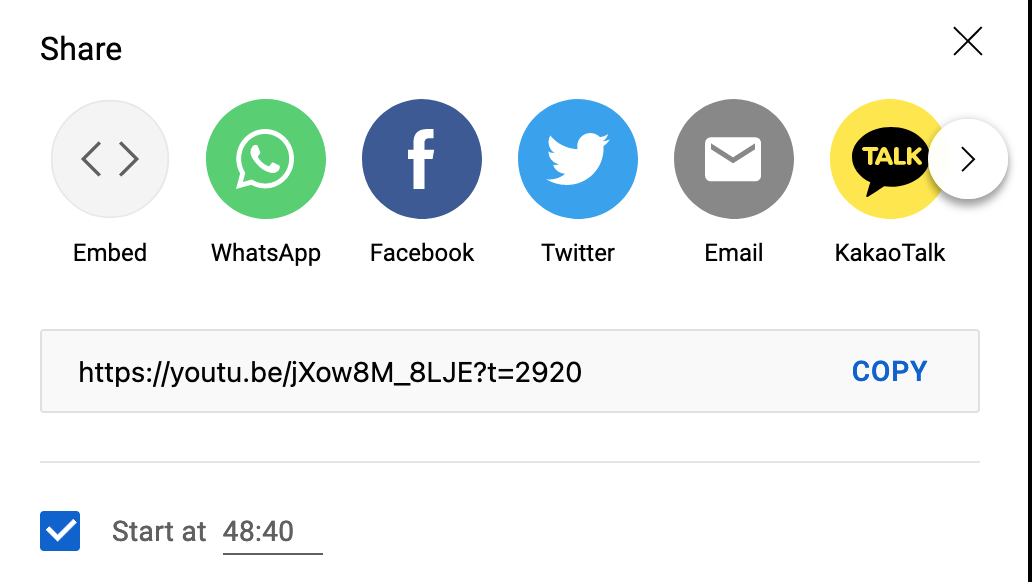
You can also share a video that will start at a specific time stamp by appending ?t= with the starting time in seconds of the area you want the video to start
https://youtu.be/[videoid]?t=[time in seconds]
Download entire channel#
Now that we have a csv file with every video ID and title of the video in it we can
use the python subprocess module to run our yt-dlp command on every video in
the channel name. yt-dlp is written in python and can be integrated into your program
without subprocess but this was quicker for me. This script will give us a directory
of vtt files named with this pattern [videoid].vtt.en.vtt
import re, subprocess
with open("tim_dillon.csv", "r") as f:
lines = f.readlines()
for line in lines:
line = line.split(";")
vid_id = line[0]
url = "https://www.youtube.com/watch?v=" + vid_id
vid_title = line[1].strip()
subprocess.run(
f"yt-dlp --write-auto-sub --skip-download -o subs/{vid_id}.vtt \"{url}\"",
shell=True)
Make a target database#
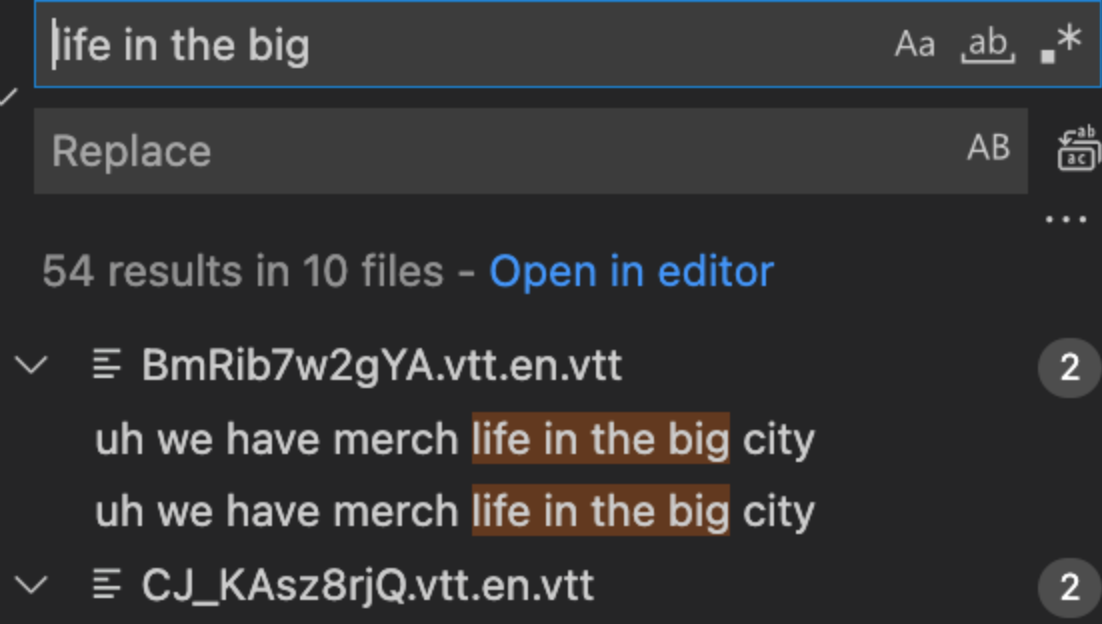
Saving all the vtt files means we have a searchable dataset and It’s up and it’s up to
us to figure out what tools we will use to search the data. We could just open up
the subtitle directories in vs code then manually figure out what our timestamped
url should be using the filename for the id and converting the time into seconds.
I chose to make a sqlite database to search the dataset with the following schema:
make_table.sql
CREATE TABLE timdillon (
vid_id TEXT,
vid_title TEXT,
start_time TEXT,
end_time TEXT,
sub_titles TEXT
);
sqlite3 yt_fts.db < make_table.sql
Populating the database#
There are some python libraries to parse vtt files but regex does the job just fine so that’s
what I did here. We use os.walk() to grab a list of every vtt file then call parse_files()
on that path which adds the captions found in those files to the database.
populate_db.py
import sys, subprocess, os
import re, sqlite3
from pathlib import Path
def main():
dir_dict = os.walk("subs")
for root, dirs, files in dir_dict:
for f in files:
full_path = os.path.join(root,f)
parse_files(full_path)
We need this for later to get the title from our current ID
def get_title_from_id(vid_id):
with open("tim_dillon.csv", "r") as f:
lines = f.readlines()
for line in lines:
line = line.split(";")
current_id = line[0]
vid_title = line[1].strip()
if vid_id == current_id:
return vid_title
Every line with a start and end time ends with the string: align:start position:0%
Ex:
01:22:26.460 --> 01:22:26.470 align:start position:0%
I have and they're dead okay they go
If we land on a line with that string we know can grab the start and end time using
regex groups to isolate the time slots in this format [start] --> [end].
start = re.search("^(.*) -->",time_match.group(1))
end = re.search("--> (.*)",time_match.group(1))
We also know that the next line will be the transcribed audio within that time frame so if we
enumerate the lines we can just add one to the current index and it should be the text we
want.
sub_titles = lines[count + 1]
Then with all these variables isolated we can send them to the database
cur.execute("INSERT INTO timdillon VALUES (?,?,?,?,?)",
(vid_id, vid_title, start_time, end_time, sub_titles))
full function:
def parse_files(full_path):
fp = Path(full_path)
vid_id = fp.stem[:11]
vid_title = get_title_from_id(vid_id)
con = sqlite3.connect("yt_fts.db")
cur = con.cursor()
time_pattern = "^(.*) align:start position:0%"
with open(full_path, "r") as f:
lines = f.readlines()
for count, line in enumerate(lines):
time_match = re.match(time_pattern, line)
if time_match:
start = re.search("^(.*) -->",time_match.group(1))
end = re.search("--> (.*)",time_match.group(1))
start_time = start.group(1)
end_time = end.group(1)
sub_titles = lines[count + 1]
cur.execute("INSERT INTO timdillon VALUES (?,?,?,?,?)",
(vid_id, vid_title, start_time, end_time, sub_titles))
con.commit()
con.close()
if __name__ == '__main__':
main()
CLI script#
Now that we have a database with a table of structured data, we need an interface for retrieving data. Ideally we don’t want to have to match the exact quote to our results so we need to use wildcards in our sql queries. Wildcards will return quotes which contain the sub string of our search text as well as exact matches. To implement wildcards we need to use the sqlite LIKE keyword:
SELECT -- return these rows
vid_id, start_time, sub_titles
FROM -- from this table
timdillon
WHERE -- where this collumn
sub_titles
SELECT -- is kinda like
'%in the big city%'
If we do get a match from the database we need to convert the start time string into seconds
so we can build our time stamped url. This means converting 01:22:26.460 into 4942.
The time_to_secs() function does this by isolating the hour minutes and seconds
with regex converting them to integers and multiplying hours by 3600 and minutes by 60
and returning the sum minus three. I subtracted three seconds because it gives the viewer
time to process what they are going to listen to.
time_rex = re.search("^(\d\d):(\d\d):(\d\d)",time_str )
hours = int(time_rex.group(1)) * 3600
mins = int(time_rex.group(2)) * 60
secs = int(time_rex.group(3))
For some reason the vtt files all repeat each line of dialog under a slightly different time
frame which is really annoying but I did not fix when entering the data into the database
so we’re dealing with it now. The id_stamp variable prevents us from repeating lines of dialog
within the same video by appending a formatted string [videoid]hh:hh:ss to a an array that we check every iteration of printing so we don’t repeat ourselves.
id_stamp = vid_id + start[:-4]
full function:
import sys, sqlite3, re
def main():
if len(sys.argv) < 2:
print("Need quote as argument")
exit(0)
else:
get_quotes(sys.argv[1])
def get_quotes(quote):
con = sqlite3.connect("yt_fts.db")
cur = con.cursor()
cur.execute("SELECT * FROM timdillon WHERE sub_titles LIKE ?",
('%'+quote+'%',))
res = cur.fetchall()
con.close()
if len(res) == 0:
print("No matches found")
else:
shown_titles = []
shown_stamps = []
for quote in res:
vid_id = quote[0]
vid_title = quote[1]
start = quote[2]
end = quote[3]
subs = quote[4]
# should look like: 6C7vx4Ot2qk01:28:00
id_stamp = vid_id + start[:-4]
time = time_to_secs(start)
if vid_title not in shown_titles:
print(f"\nMatches found in: \"{vid_title}\"")
shown_titles.append(vid_title)
if id_stamp not in shown_stamps:
print(f"\n")
print(f" Quote: \"{subs.strip()}\"")
print(f" Time Stamp: {start}")
print(f" Link: https://youtu.be/{vid_id}?t={time}")
shown_stamps.append(id_stamp)
def time_to_secs(time_str):
time_rex = re.search("^(\d\d):(\d\d):(\d\d)",time_str )
hours = int(time_rex.group(1)) * 3600
mins = int(time_rex.group(2)) * 60
secs = int(time_rex.group(3))
total_secs = hours + mins + secs
return total_secs - 3
if __name__ == '__main__':
main()
After all this we should have a cli that takes a string as an argument and returns
the stamped urls with full quotes for everything it finds matching that string.
shortened sample
[$] python3 yt_fts.py "in the big city"
Matches found in: "164 - Life In The Big City"
Quote: "life in the big city it was one of my"
Time Stamp: 00:27:17.549
Link: https://youtu.be/dqGyCTbzYmc?t=1634
Quote: "life in the big city my mother would go"
Time Stamp: 00:27:33.210
Link: https://youtu.be/dqGyCTbzYmc?t=1650
Quote: "saying life in the big city he had a few"
Time Stamp: 00:28:00.990
Link: https://youtu.be/dqGyCTbzYmc?t=1677
It would be better if this interface would was something like react emoji search but the last time I dove into javascript the night terrors didn’t stop for several months.