Exporting your contacts the hard way

Exporting your contacts and other data from an iPhone is much harder than it looks, especially with out an iCloud account. It’s not as easy as plugging your iPhone into a computer and clicking a button. This post goes over the steps I went through to export my media and contacts from an iTunes backup. I learned much of this while building an iOS forensics tool at a hackathon. If you’re looking for a somewhat out of the box solution go give it a shot.
Creating an iTunes backup#
While MacOS provides a “phone file browser” built into Finder it only displays limited
data. Excluding things like your contacts, photos, voice memos and messages.
It still technically backs up this data however it only does so in a format to
be read by restoring the backup on to an iPhone. In order to make one of these backups on MacOS your
device needs to have enough storage on disk and Finder does not provide a
way to make backups on external drives. You can get around this by
creating a symbolic link to an external drive in the
~/Library/Application\ Support/MobileSync/Backup directory.
This can be done with the following command, substitute Untitled with the
name of the drive you mounted.
sudo ln -s /Volumes/Untitled/Backup/ ~/Library/Application\ Support/MobileSync/Backup
Next plug in your iPhone and browse to the finder window where you phone pops up.
It’s important that when you click Back Up Now that you have not selected the
option encrypt local backup. Once your backup starts you files should be
exporting to your external drive or whatever folder you chose for the backup.
Understanding the backup structure#
After the back up is complete, if you navigate to the external folder you should
see a file structure similar to this:
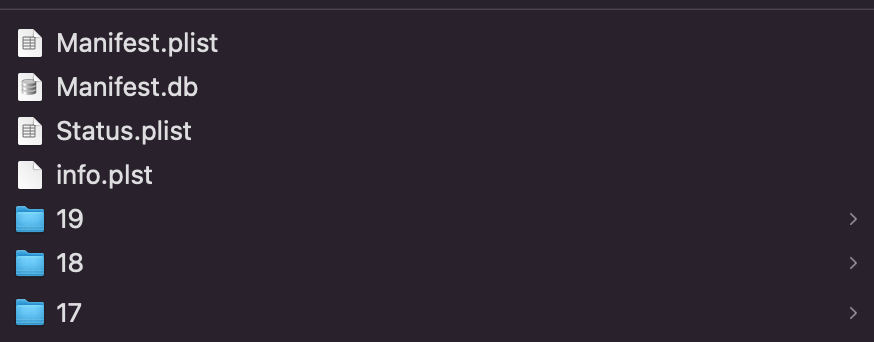
I’m not sure what the .plist files do but you won’t
need them for exporting contacts and media. Depending
on the size of your backup you might have well over a
hundred nondescript directories containing about
a hundred individual files each. All named with 40 character
strings and no file extensions.
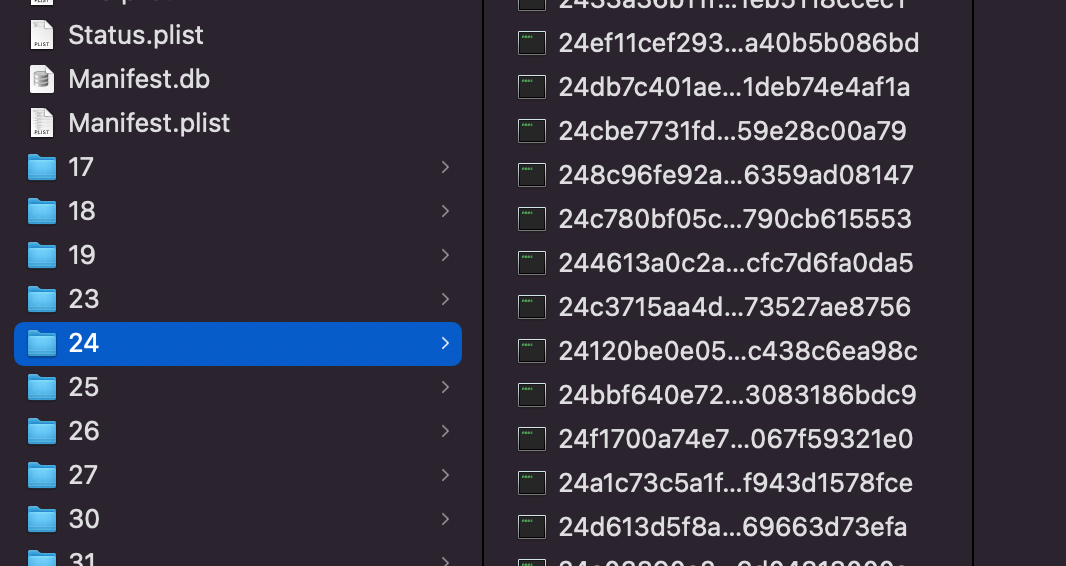
If you preview these files with finder you’ll probably see some familiar images.
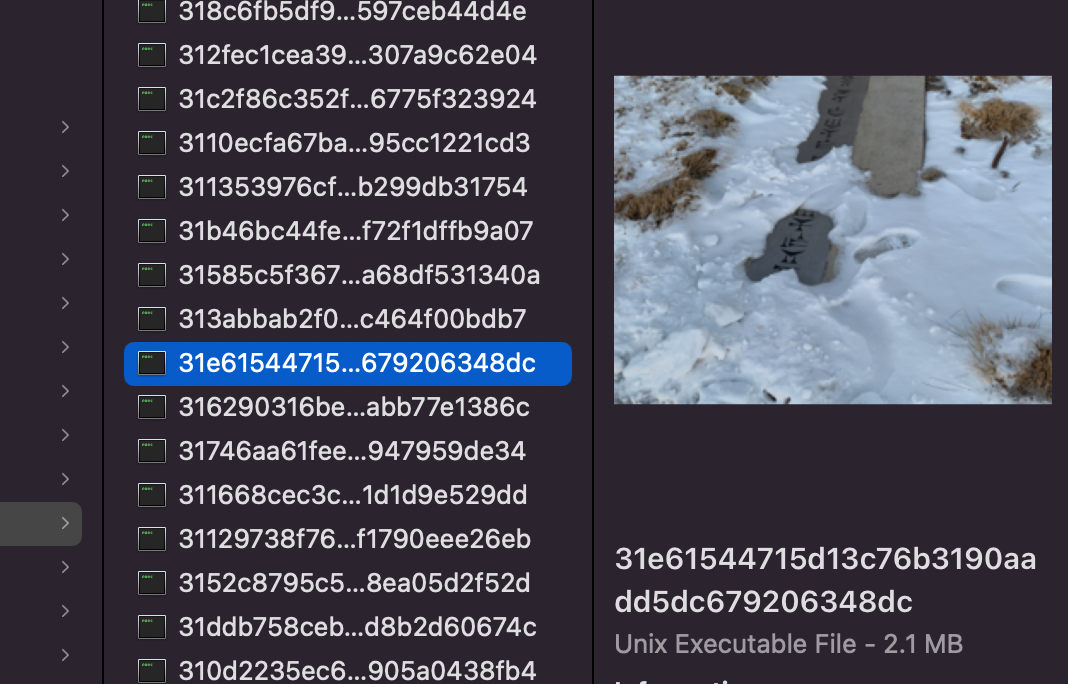
Even though these are all named as “Unix Executable” they all hold data that can be accessed by attaching the correct file extension. If we attached the correct file extension we can view the data as intended.
Check out this cool picture I got outside the
RAWLS College of Business during a snow storm last year

Manifest.db#
According to this blog post by Rich Infante, Manifest.db
is an sqlite database file with two tables
FilesfileIDTEXT PRIMARY KEY the name of the file in the backup (derived from a hash)domainTEXT What sandbox the file is inrelativePathTEXT File relative to domainflagsINTEGER Unix file flagsfileBLOB - Binary plist containing poperties
Properties- Two fields:
keyTEXT PRIMARY KEY, valueBLOB
- Two fields:
If we open the Manifest.db with the sqlite3 CLI and query
the Files table for the name of the file we
just looked at, it returns a row with more detailed data
about the file.
sqlite3 Manifest.db
sqlite> .mode markdown
sqlite> SELECT fileID,domain,relativePath,flags FROM Files WHERE fileID='31e61544715d13c76b3190aadd5dc679206348dc';
Returns:
| fileID | domain | relativePath | flags |
|---|---|---|---|
| 31e61544715d13c76b3190aadd5dc679206348dc | CameraRollDomain | Media/DCIM/104APPLE/IMG_4224.JPG | 1 |
The CamraRollDomain in the domain column tells us that it’s probably a media file. We can use this method
to write a script that helps us narrow down the file extensions for every file in our
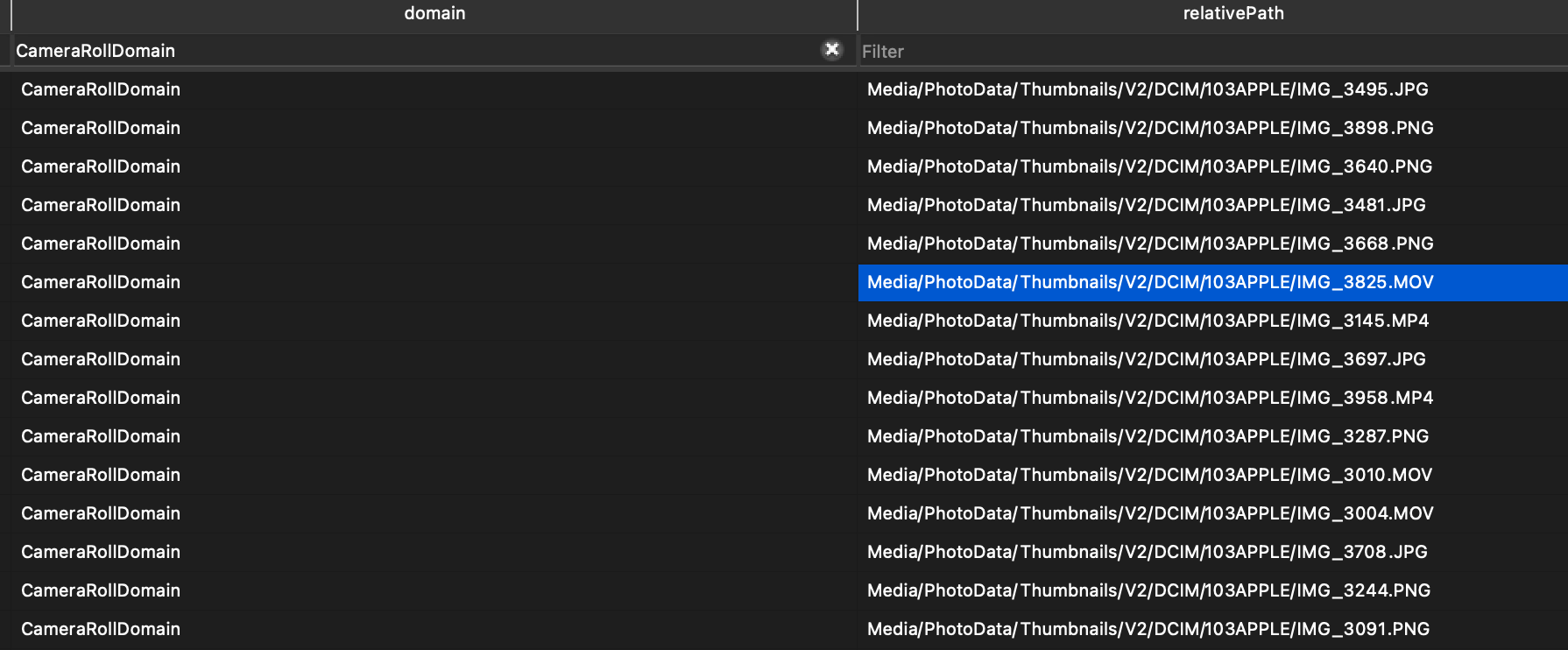
backup. But if we open up the database in a tool like DB Browser for SQLite and search for CamraRollDomain
it quickly becomes apperent that CamraRollDomain is a broad label for
several diffrent filetypes in the backup.
Determining the datatypes with the file command#
file is a unix command
available on MacOS that will attempt to classify any filetype you feed it, file
determines the filetype based off the internal data, it does not require a file extension and
can even determine a file type with a false extension.
This is really helpful for checking sketchy files before opening them.
Ex:
$ file totally_not_malicous.pdf
report.pdf: Mach-O 64-bit executable x86_64
python-magic#
We could write a shell script to run file on all the artifacts in our backup like
this:
find . -type f -exec file {} \; | grep "JPEG"
But to prevent things from getting messy it’s better to access the file commands
functionality with the python-magic library.
import magic
f = magic.Magic(mime=True)
ftype = f.from_file("31e61544715d13c76b3190aadd5dc679206348dc")
print(ftype) # image/jpeg
We can now write some code to get the file type of every artifact in the backup
# Recursively finds all files in the backup
def find_ftypes(filepath="/path/to/Backup"):
for root, dir, files in os.walk(filepath):
for file in files:
full_path = f"{root}/{file}"
f = magic.Magic(mime=True)
ftype = f.from_file(full_path)
print(full_path,ftype)
find_ftypes()
/path/to/Backup/34/346445c16e04454cd1375049cde7404cf6fd23ce video/quicktime
/path/to/Backup/34/3442966c9885693f90f8319c4f6a012fd178c7fa video/mp4
/path/to/Backup/34/34e444518662a86f6c0accba86c9d3a556607b8a image/png
/path/to/Backup/34/34e7273bd0bad66974b6f574e2de5943f724274b image/jpeg
And with a little more logic we can copy each filetype to another directory with the proper file extension:
import magic, os, shutil
def find_ftypes(filepath="/path/to/Backup"):
for root, dir, files in os.walk(filepath):
# Make directories
os.makedirs("media/jpeg",exist_ok=True)
os.makedirs("media/mp4",exist_ok=True)
os.makedirs("media/png",exist_ok=True)
os.makedirs("media/mov",exist_ok=True)
for file in files:
full_path = f"{root}/{file}"
f = magic.Magic(mime=True)
ftype = f.from_file(full_path)
# check mime type and copy to respective directory
if ftype == "image/jpeg":
shutil.copyfile(full_path, f"./media/jpeg/{file}.jpeg")
if ftype == "image/png":
shutil.copyfile(full_path, f"./media/png/{file}.png")
if ftype == "video/mp4":
shutil.copyfile(full_path, f"./media/mp4/{file}.mp4")
if ftype == "video/quicktime":
shutil.copyfile(full_path, f"./media/mov/{file}.MOV")
find_ftypes()
Exporting Contacts#
Retrieving your contacts is a bit more tricky. A search for the
keyword contacts in the Manifest.db returns over 20
rows and none of them contain the right file path. To find the contacts file we
need to search for a row with a colum value relativePath='Library/AddressBook/AddressBook.sqlitedb'.
I found this thanks to the iLEAPP project
(An iOS forensics tool written in python). The project has a very
helpful dictionary with paths to many sqlite databases for common things like contacts, notes & safari bookmarks.
Reading the AdressBook database#
We can find the file name of the AdressBook database with the
following query.
sqlite3 Manifest.db "SELECT fileID FROM Files WHERE relativePath='Library/AddressBook/AddressBook.sqlitedb'"
31bb7ba8914766d4ba40d6dfb6113c8b614be442
Then we can find this file in the backup with the find command and save it to another directory to work on
cd /path/to/Backup
find . -name "31bb7ba8914766d4ba40d6dfb6113c8b614be442"
cp path/to/file/31bb7ba8914766d4ba40d6dfb6113c8b614be442 /path/to/other/AdressBook.db
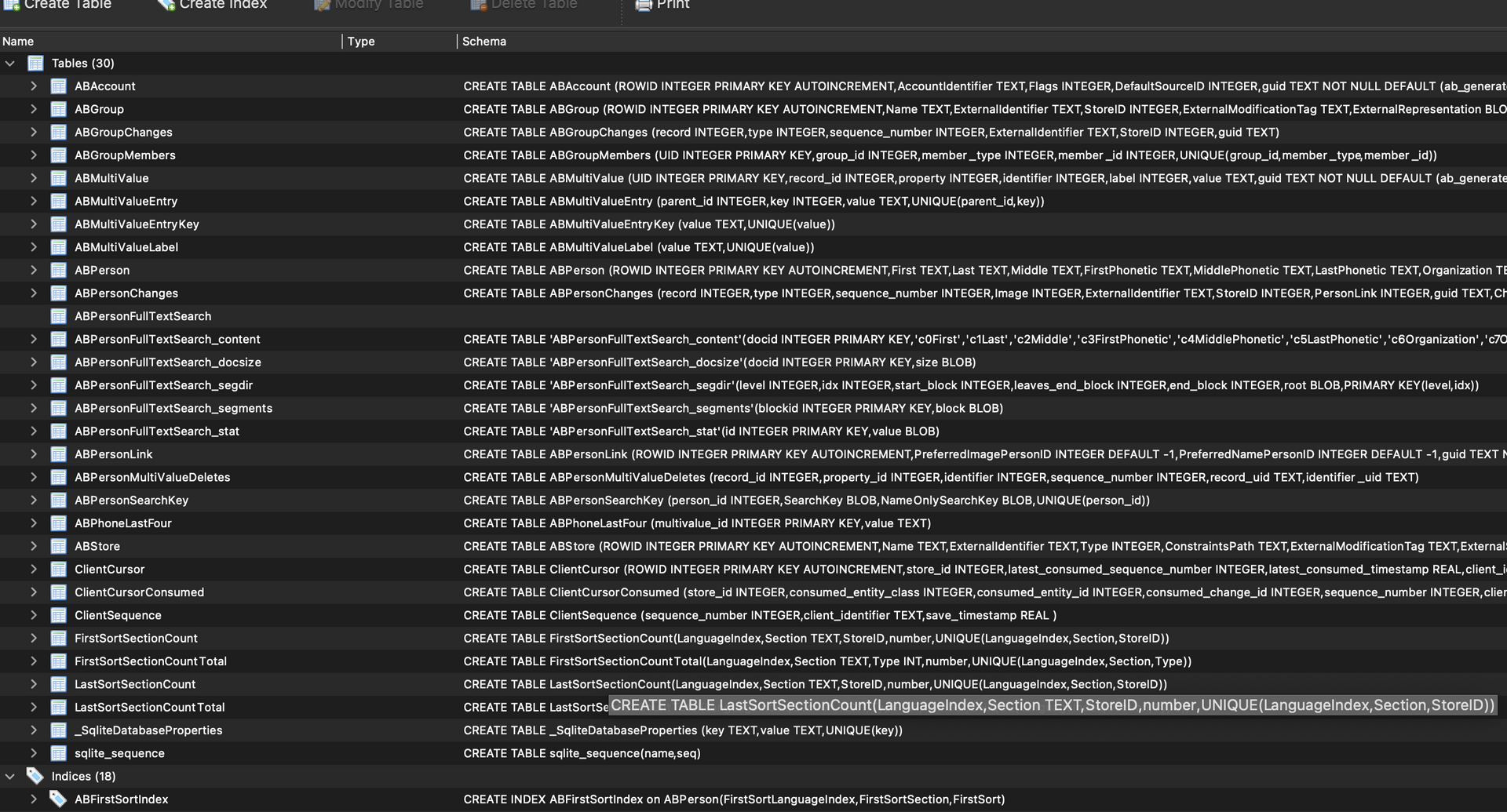
When I opened this file in sqlite viewer I was amazed at the complexity
It has over 20 tables and what I’m assuming are virtual tables for full text
search features
I managed to find a table with phone number but they were missing the corresponding names
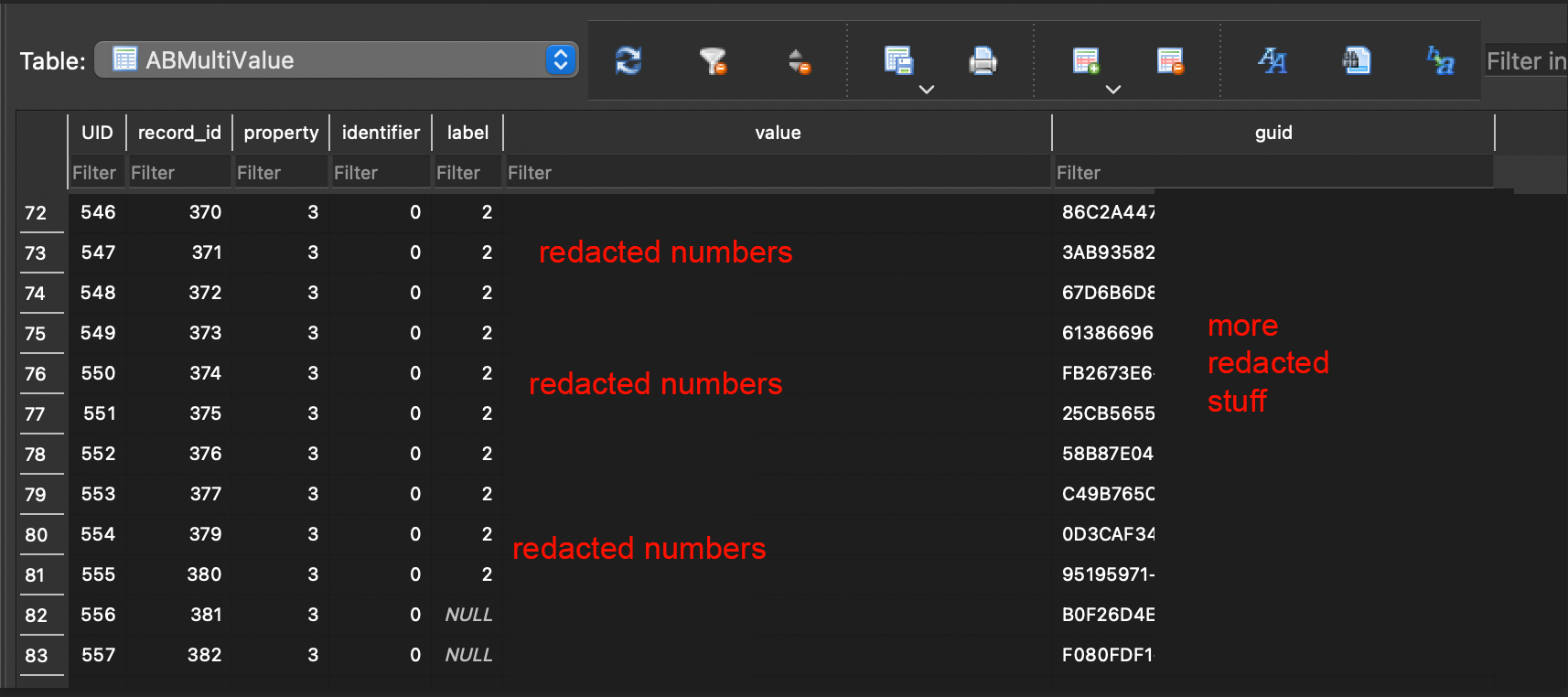
Fortunately the iLEAPP project already went through the hassle of building a query that will return the names, numbers and other notes you attached to the contact. We can borrow this query and run it in a python script like this:
import sqlite3, csv
con = sqlite3.connect("AdressBook.db")
cur = con.cursor()
cur.execute("""
SELECT
ABPerson.ROWID,
c16Phone,
FIRST,
MIDDLE,
LAST,
c17Email,
DATETIME(CREATIONDATE+978307200,'UNIXEPOCH'),
DATETIME(MODIFICATIONDATE+978307200,'UNIXEPOCH'),
NAME
FROM ABPerson
LEFT OUTER JOIN ABStore ON ABPerson.STOREID = ABStore.ROWID
LEFT OUTER JOIN ABPersonFullTextSearch_content on ABPerson.ROWID = ABPersonFullTextSearch_content.ROWID
""")
res = cur.fetchall()
con.close()
csv_list = []
for row in res:
if row[1] is not None:
numbers = row[1].split(" +")
number = numbers[1].split(" ")
phone_number = "+{}".format(number[0])
else:
phone_number = ''
contact_id = row[0]
first_name = row[2]
last_name = row[4]
csv_list.append([contact_id, phone_number, first_name, last_name])
with open("contacts.csv", "w") as f:
writer = csv.writer(f, delimiter=",")
writer.writerow(['contact_id','phone_number', 'first_name', 'last_name'])
for row in csv_list:
writer.writerow(row)
This should write out a csv file named contacts.csv with the
format:
| contact_id | phone_number | first_name | last_name |
|---|
Resources#
- iLEAPP iOS Logs, Events, And Plists Parser
- Reverse Engineering the iOS Backup by Rich Infante
- ios_backup_browser command-line tool I wrote that does everything in this post