Solving wordle with grep

Grabbing the word list#
To narrow down our word guesses it would help to know what list wordle uses, apparently it’s hardcoded into the javascript on the site. I found this wget command to mirror an entire site offline and I used this to get the source code for wordle.
$ wget --mirror --page-requisites --convert-links --adjust-extension --compression=auto --no-if-modified-since --no-check-certificate https://www.nytimes.com/games/wordle/index.html
Turns out worlde is now owned by
the NewYork Times and https://www.powerlanguage.co.uk/wordle will now route you to the NewYork times domain.
Anyway, after running this command you should have a folder named www.nytimes.com
$ tree www.nytimes.com
www.nytimes.com
├── games
│ └── wordle
│ ├── fonts
│ │ ├── franklin-normal-500.woff
│ │ ├── franklin-normal-500.woff2
│ │ ├── franklin-normal-700.woff
│ │ ├── franklin-normal-700.woff2
│ │ ├── karnakcondensed-normal-700.woff
│ │ └── karnakcondensed-normal-700.woff2
│ ├── images
│ │ ├── nav-icons
│ │ │ ├── Crossword-Icon-Normalized-Color.svg
│ │ │ ├── Crossword-Icon-Normalized.svg
│ │ │ ├── LetterBoxed-Icon-Normalized-Color.svg
│ │ │ ├── LetterBoxed-Icon-Normalized.svg
│ │ │ ├── Mini-Icon-Normalized-Color.svg
│ │ │ ├── Mini-Icon-Normalized.svg
│ │ │ ├── SpellingBee-Icon-Normalized-Color.svg
│ │ │ ├── SpellingBee-Icon-Normalized.svg
│ │ │ ├── Sudoku-Icon-Normalized-Color.svg
│ │ │ ├── Sudoku-Icon-Normalized.svg
│ │ │ ├── Tiles-Icon-Normalized-Color.svg
│ │ │ ├── Tiles-Icon-Normalized.svg
│ │ │ ├── Vertex-Icon-Normalized-Color.svg
│ │ │ └── Vertex-Icon-Normalized.svg
│ │ ├── wordle_logo_192x192.png
│ │ └── wordle_logo_32x32.png
│ ├── index.html
│ ├── main.bd4cb59c.js
│ └── manifest.json
├── games-assets
│ ├── gdpr
│ │ └── cookie-notice-v2.1.2.min.js
│ └── v2
│ └── metadata
│ ├── nyt-apple-touch-icon.png?v=v2202021345
│ └── nyt-safari-pinned-tab.svg?v=v2202021345
└── robots.txt
Only thing we need are what’s in the www.nytimes.com/games/wordle directory
Cleaning up the javascript#
main.bd4cb59c.js is a minified js file with the wordlist used for the game
Using the Beutify plugin from vs code we can make this a bit
more readable
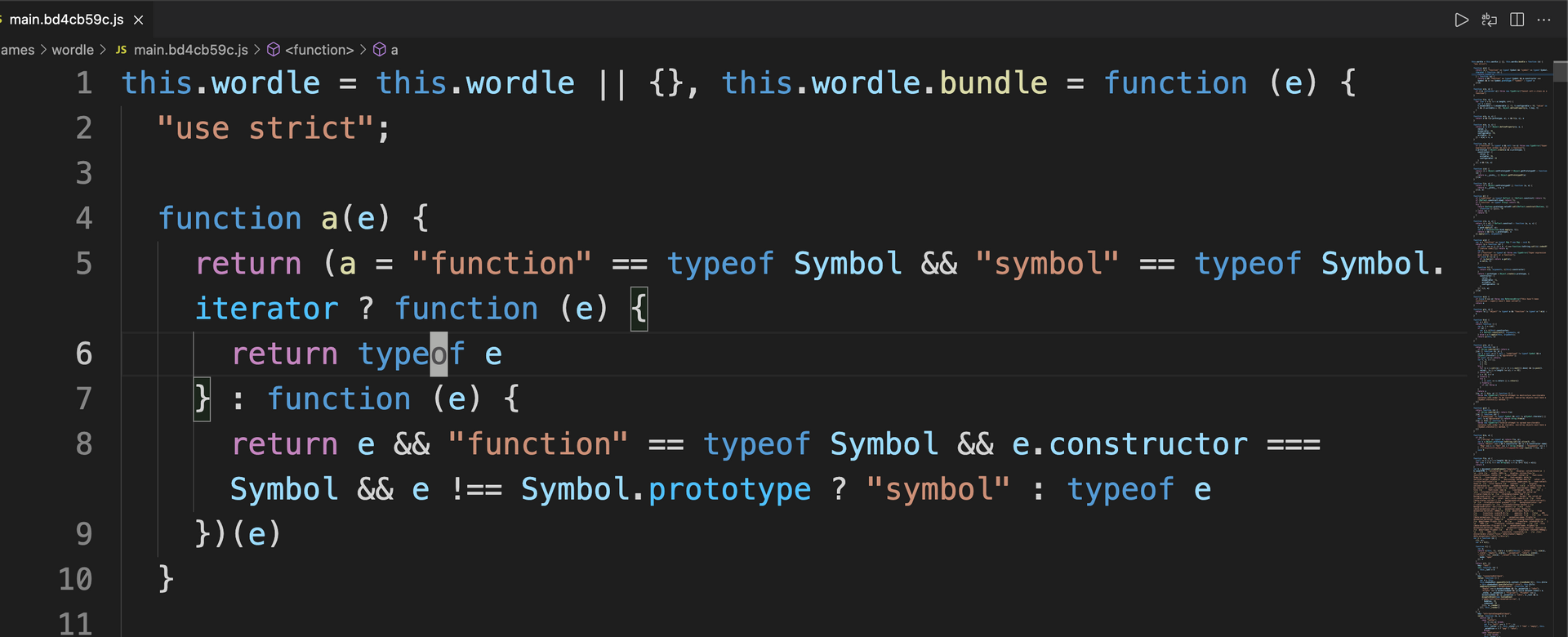
Before#

After#
Making our own wordlist#
Scrolling down a little we can see that there are two variables
that contain large the full word list Ma and Oa
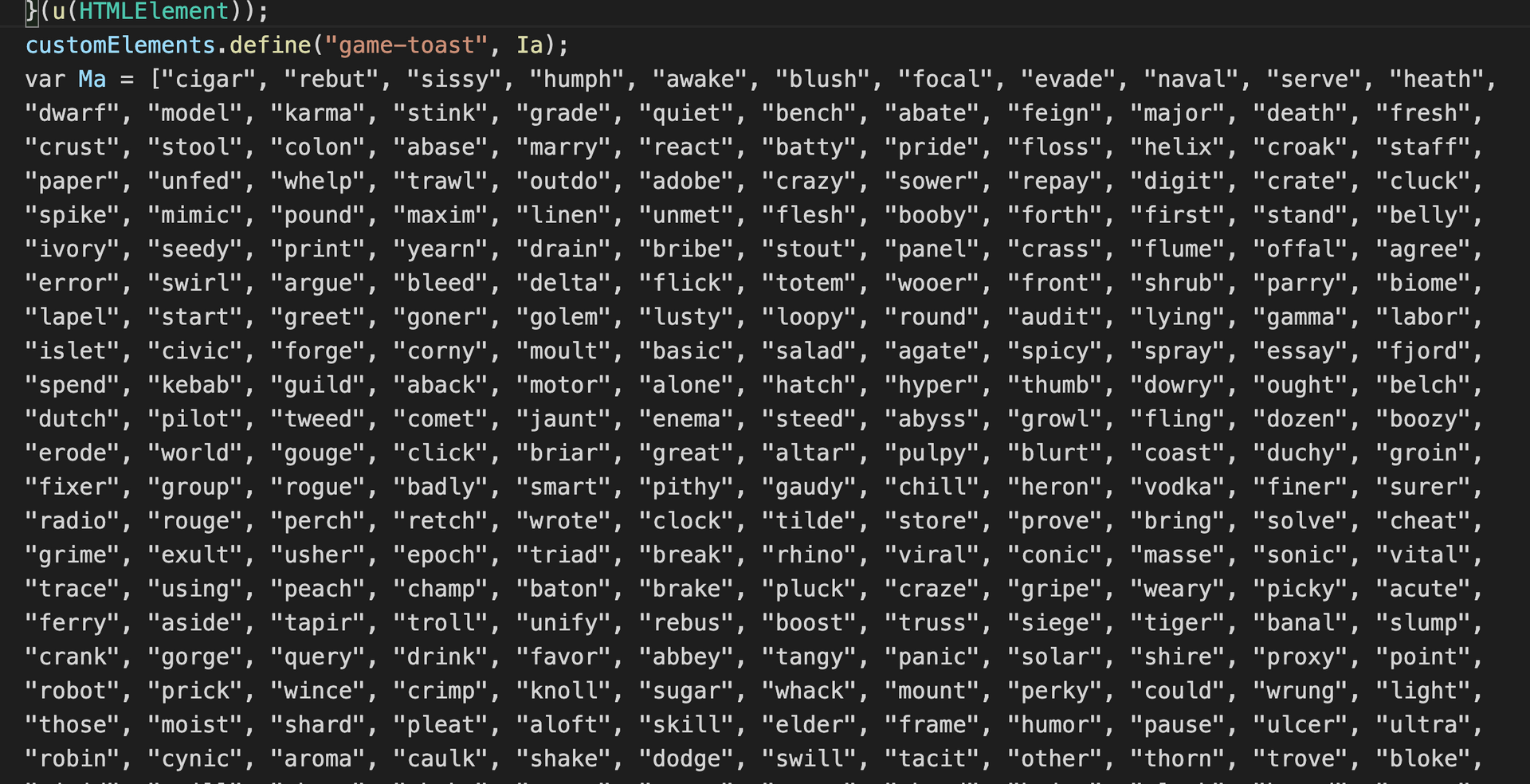
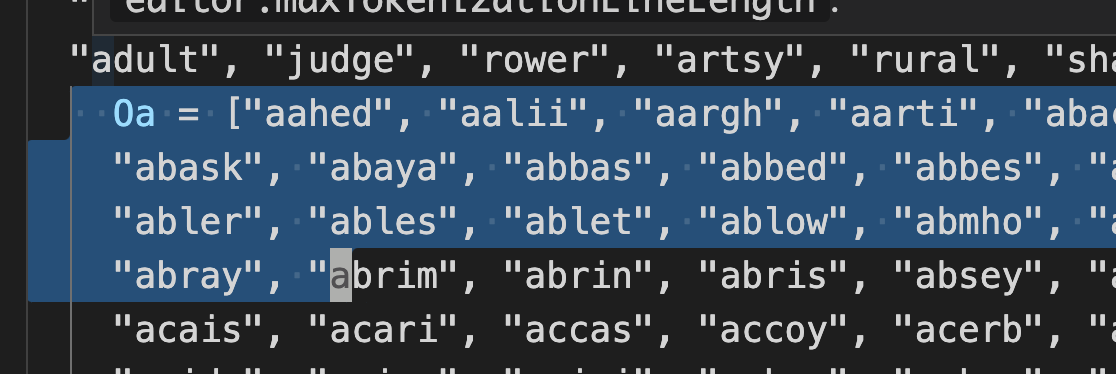
We can copy these two variables to a new python file and treat them as a normal list.
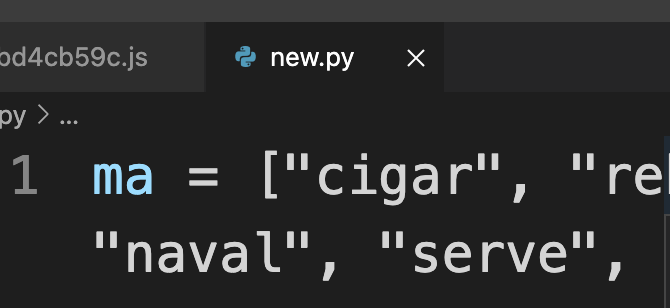
Then we can print both of them out and count how many valid words are posible which is 12,947
for i in ma:
print(i)
for x in oa:
print(x)
python3 new.py | wc -l
12947
Now we can save this to a new file
python3 new.py >> wordlist.txt
Side note about the New York Times buyout#
I had a copy of this site when it was hosted on www.powerlanguage.co.uk
and it looks like the NewYork times removed some unsavory words the word list. Probably a good idea considering this is family game.
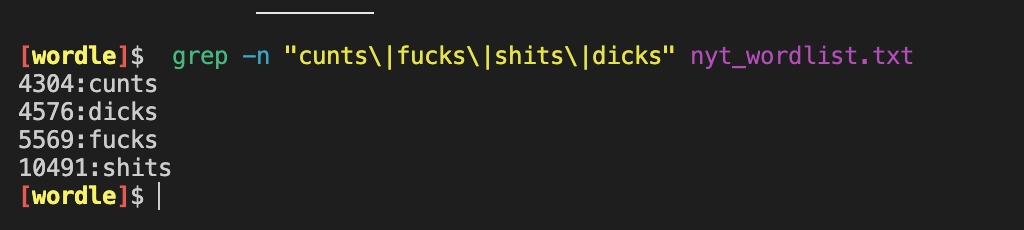
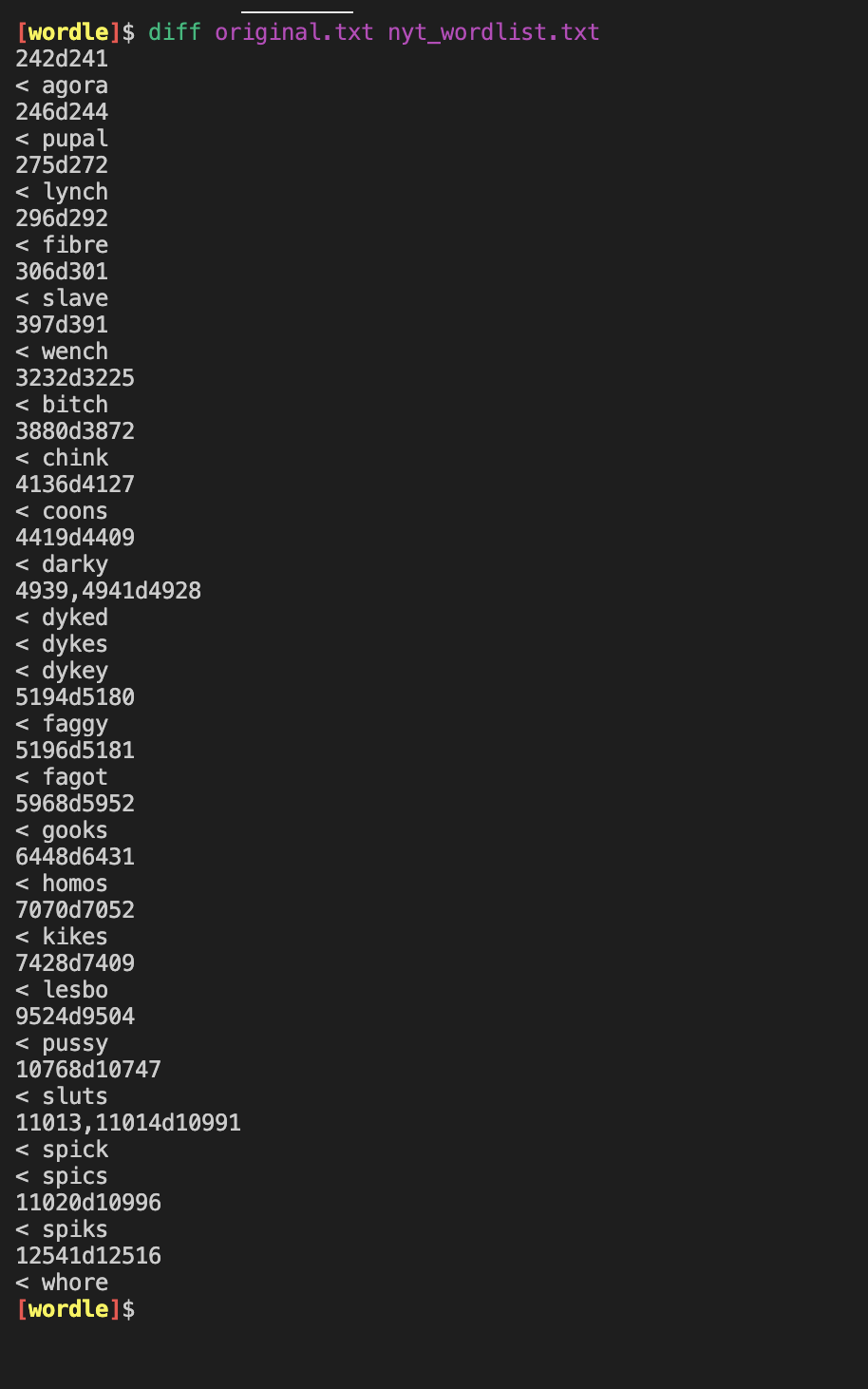 However they should probably do a couple more word searches
However they should probably do a couple more word searches
Anyway with the words saved to a list we can randomly select one for our first guess
shuf -n 1 wordlist.txt
varix
 What does this tell us?
What does this tell us?
Well we now know that the word does not contain the letters v, a, r, or x and it must have the letter i in the 4th index.
to simulate this logic in grep we need to use the -v
option which allows us to invert our match, basically a NOT operator.

to make this faster we can also add an OR operator using \|
as our match string. so if we wanted all words from our list not containing
the characters v or a or r or or x we can use this
cat wordlist.txt | grep -v 'v\|a\|r\|x'
zoppo
zouks
zowee
zowie
zulus
zuzim
zygon
zymes
zymic
This narrows our list down to 4,947
cat wordlist.txt | grep -v 'v\|a\|r\|x' | wc -l
4947
We also need to filter out all of the words that don’t have an i in
the 4th position which can be done with the -E flag
that let’s us use more RegEx with grep I guess

this is grep command to match all words with i as the 4th letter
grep -E "...i."
When combined with our previous commands it narrows our wordlist down to 341 words.
cat wordlist.txt | grep -v 'v\|a\|r\|x' | grep -E "...i." | wc -l
341
Let’s randomly select one word from this new list
cat wordlist.txt | grep -v 'v\|a\|r\|x' | grep -E "...i." | shuf -n 1
No luck but we do get some more hints

now we can add o,f and e to as new filters in our grep command which narrows our search down to 117 words.
cat wordlist.txt | grep -v 'v\|a\|r\|x\|o\|f\|e' | grep -E "...i." | wc -l
117
Let’s get another random word
cat wordlist.txt | grep -v 'v\|a\|r\|x\|o\|f\|e' | grep -E "...i." | shuf -n 1
tiyin
better luck

we now know that N and Y are in the word but Y is not in index 3 and N is not in index 5, we also know I only appears in the word once and T is not in the word. To get the best out of this we need an expression that can count how often I appears in the word and an expression that ensures Y and N can only appear in the first two indexes
we can the letter t to our ignore command
grep -v 'v\|a\|r\|x\|o\|f\|e\|t'
this command uses regex quantifier to exclude all words that contain
an i character more than once
grep -vE '([^i]*i){2,}'
Now we want to exclude all words that end with yin
grep -vE "..yin"
But we still only want words that contain y and n
so we can string these two statements together and it
will work as an AND operator. Putting it all together the commands looks like this
cat wordlist.txt | grep -v 'v\|a\|r\|x\|o\|f\|e\|t' | grep -E "...i." | grep -vE '([^i]*i){2,}' | grep -vE "..yin" | grep "y" | grep "n"
Leaving us with three words to pick from
cynic
kylin
lysin
I’ll chose cynic because it’s the most word like option.
Perfect
